kafka 的创建topic 流程(一)更新中 kafka 版本 2.6 创建一个 topic 后,kafka 底层做了什么?生成了什么元数据以及存放在哪? topic 的分区数目是如何分布在各个节点的? 通过命令创建 一个副本数为 1 ,分区数为 1 的 topic,先看看底层发生了什么,然后在分析流程 kafka 日志目录一个分区对应一个目录,文件有 索引文件和日志文件 1234567891011(base) user@userd 2024-10-12 大数据 #Kafka
kafka 的删除策略 前段时间客户咨询了个Kafka过期策略删除的问题,趁着机会,深入理解下 kafka 日志数据若是设置了清除策略,会按照策略定期清除kafka log 数据,清除方式有两种 清除策略有有两种,分别是compact 和 delete ,两者都能达到释放空间的效果,这里介绍触发的机制和相关参数 从配置文件看参数: log.retention.hours/ log.retention.mi 2024-10-11 大数据 #Kafka
编译过程<2>(目标文件) 前言从源码到可执行文件,中间的过程中会生成 .o 文件,也就是目标文件,目标文件放的是什么呢?前面经常用objdump 反汇编过,似乎是以莫种格式存放的,什么格式呢? 可执行文件又是什么格式呢? 本文只讨论Linux下的目标文件 目标文件的格式我们先用 file 命令查看 12345678hrp@ubuntu:~$ file mainmain: ELF 64-bit LSB shared obj 2024-04-19 linux #c++
性能定位过程 前言近期做一些性能调优的事,很折腾人,麒麟的OS 和 centos OS 读写性能差距很大,尤其是大块读写,相同物理环境,相同的产品,OS不同,差距为什么会如此之大,我也知道 OS 不同,内核版本不同,内核的参数也不同,性能肯定会受影响,但内核的参数我也就知道几个,只好摸石头过河,边学边干了,这过程中学到了很多新的东西,这里记录下过程 怀疑是到磁盘的瓶颈了,于是压测时 用 iostat 看,uti 2024-03-20 #Linux
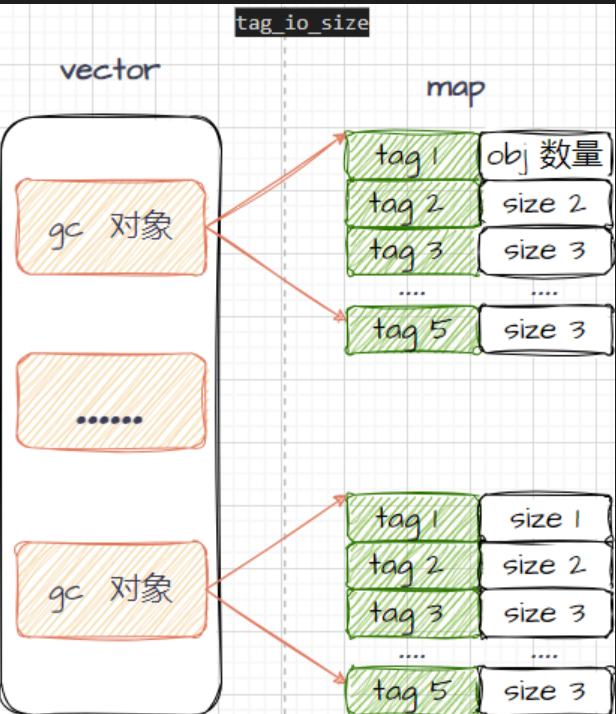
ceph中的cls调用流程 这次介绍下cls 的调用流程(类似于RPC) 以gc 流程为例; 删除 对象后,会在gc obj 上记录已经删除的信息,以 omap 形式存在,gc list 则可以看到 gc上的omap,这个功能实现就是通过用 cls 实现的, 所以 我们gdb 进去看看,调用流程 1gdb -args ./bin/radosgw-admin gc list --include-all 结合源码,我知道 2024-03-12 #ceph
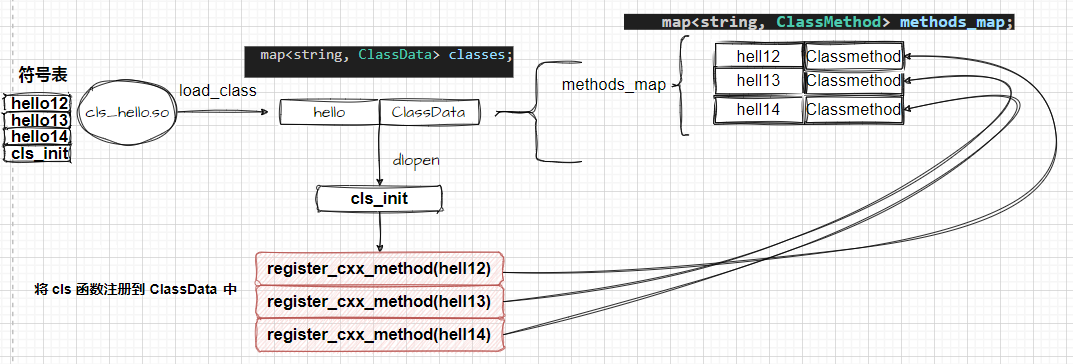
ceph中cls 实现 概览ceph提供了librados API来访问后端rados存储集群,上层业务都是基于 rados 提供的接口实现的 随着项目规模的扩大,最初提供的简单增删改查 API 虽然能够满足基本业务需求,但在特殊场景下可能需要额外的 API 接口。逐渐增加的业务需求导致业务逻辑变得更加复杂,因此提供的 API 数量也会不断增加,这可能会使得底层的 RADOS 层变得臃肿,从解耦方面来看,特定的业务逻 2024-03-12 #ceph
rclone拷贝桶对象失败定位过程 背景某客户 有一套杉岩的对象存储环境(医疗图片),里面的桶容量快满了,于是想把这桶的数据迁移到 我们的集群,于是rclone 工具将 衫岩的的数据拷贝过来,但是总是失败。 2024-03-11 #ceph
编译过程<1>(编译和链接) 前言一个c语言文件是怎么转换成 可执行文件的呢? 中间有什么过程呢? 编译器 起着什么作用呢? 如何转换可执行文件?我们编译的时候要么用 ide 帮我编译程序,要么自己敲命令,我们后者为例,使用gcc 编译一个c文件 1234567891011121314hrp@ubuntu:~$ cat hello.c #include <stdio.h>int main() { 2024-03-11 linux #c++