Last updated on 8 months ago
ceph中RBD 建立 image后,可以map到操作系统,当磁盘使用和插入STAT一样,此外内核模块已经支持 rbd(krbd), modinfo 可以查看内核模块;创建100g的image并不是在真实磁盘中占用了100g,而是用多少,在ceph中就占用多少

创建RBD发生了什么
现在创建pool,名字为rbd,并在rbd pool里创建image
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| [root@node29 hrp]# rados lspools
pool_A1
pool_A2
pool_rack
rbd
[root@node29 hrp]# rbd create foo --size 10240
[root@node29 hrp]# rbd -p rbd ls
foo
#查看rbd信息
# [root@node29 hrp]
rbd image 'foo':
size 10 GiB in 2560 objects
order 22 (4 MiB objects) #22是次方 4M是22, 8M是23,因为2^22 bytes = 4MB, 2^23 bytes = 8MB
snapshot_count: 0
id: 87fa3437b808
block_name_prefix: rbd_data.87fa3437b808 #每个块 唯一的前缀编号
format: 2 # 有两种格式,1 和 2 ,两者区别只是 data的obj命名不同
features: layering #这里特性 在其他文章有提过
op_features:
flags:
create_timestamp: Tue Aug 2 16:31:58 2022
access_timestamp: Tue Aug 2 16:31:58 2022
modify_timestamp: Tue Aug 2 16:31:58 2022
|
现在r bd pool里建了rbd,看看此时产生了什么数据
1
2
3
4
5
6
| [root@node29 hrp]
rbd_directory
rbd_info
rbd_id.foo
rbd_header.87fa3437b808
[root@node29 hrp]
|
建立 foo 后,生成了 rbd_id.foo,现在 查看下 rbd_directory 这个对象的内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| [root@node29 hrp]
id_87fa3437b808
value (7 bytes) :
00000000 03 00 00 00 66 6f 6f |....foo|
00000007
name_foo
value (16 bytes) :
00000000 0c 00 00 00 38 37 66 61 33 34 33 37 62 38 30 38 |....87fa3437b808|
00000010
You have new mail in /var/spool/mail/root
[root@node29 hrp]
00000000 69 64 5f 38 37 66 61 33 34 33 37 62 38 30 38 0a |id_87fa3437b808.|
00000010 76 61 6c 75 65 20 28 37 20 62 79 74 65 73 29 20 |value (7 bytes) |
00000020 3a 0a 30 30 30 30 30 30 30 30 20 20 30 33 20 30 |:.00000000 03 0|
00000030 30 20 30 30 20 30 30 20 36 36 20 36 66 20 36 66 |0 00 00 66 6f 6f|
00000040 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 | |
00000050 20 20 20 20 20 20 20 20 20 20 20 20 20 20 7c 2e | |.|
00000060 2e 2e 2e 66 6f 6f 7c 0a 30 30 30 30 30 30 30 37 |...foo|.00000007|
00000070 0a 0a 6e 61 6d 65 5f 66 6f 6f 0a 76 61 6c 75 65 |..name_foo.value|
00000080 20 28 31 36 20 62 79 74 65 73 29 20 3a 0a 30 30 | (16 bytes) :.00|
00000090 30 30 30 30 30 30 20 20 30 63 20 30 30 20 30 30 |000000 0c 00 00|
000000a0 20 30 30 20 33 38 20 33 37 20 36 36 20 36 31 20 | 00 38 37 66 61 |
000000b0 20 33 33 20 33 34 20 33 33 20 33 37 20 36 32 20 | 33 34 33 37 62 |
000000c0 33 38 20 33 30 20 33 38 20 20 7c 2e 2e 2e 2e 38 |38 30 38 |....8|
000000d0 37 66 61 33 34 33 37 62 38 30 38 7c 0a 30 30 30 |7fa3437b808|.000|
000000e0 30 30 30 31 30 0a 0a |00010..|
000000e7
|
从信息可以看到 信息包含了 刚才建立的image foo,从 rbd_directory可以猜测 这对象可能是保存 image信息的,现在再建立一个 rbd
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| [root@node29 hrp]
[root@node29 hrp]
rbd_directory
rbd_id.bar
rbd_id.foo
rbd_header.881e37e3e168
rbd_header.87fa3437b808
rbd_info
[root@node29 hrp]
[root@node29 hrp]
name_bar
name_foo
|
太多信息,过滤了其他其他内容,不过可以确定的是,每次创建一个rbd,都会pool里面rbd_directory 添加数据信息,而且还会添加 一个 rbd_header开头的 obj,rbd_header后面跟的是一个id,可以 再 rbd info看到
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| [root@node29 hrp]
rbd image 'foo':
size 10 GiB in 2560 objects
order 22 (4 MiB objects)
snapshot_count: 0
id: 87fa3437b808
block_name_prefix: rbd_data.87fa3437b808
format: 2
features: layering
op_features:
flags:
create_timestamp: Tue Aug 2 16:31:58 2022
access_timestamp: Tue Aug 2 16:31:58 2022
modify_timestamp: Tue Aug 2 16:31:58 2022
[root@node29 hrp]
[root@node29 ~]
value (1 bytes) :
00000000 16 |.|
00000001
[root@node29 ~]
value (8 bytes) :
00000000 01 00 00 00 00 00 00 00 |........|
00000008
|
 (补充 info 里面 feature)
(补充 info 里面 feature)
可以得出,每创建一个 rbd 会在 pool里 生产 rbd_id.{name }和 rbd_header.{id}这两个 obj,并且也会更新 池中rbd_directory 的内容(可以理解一个目录,现在加了新的内容,要更新目录), rbd_header.{id} 里面包含了 image 的配置信息
使用时底层发生什么
1
2
3
4
5
6
7
8
9
10
11
12
13
|
[root@node29 hrp]
bar
foo
[root@node29 hrp]
/dev/rbd1
[root@node29 hrp]
[root@node29 mnt]
/dev/rbd1 10G 33M 10G 1% /mnt/foo
[root@node29 mnt]
|
文件系统建立后,查看 rdb pool增加的内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| [root@node29 home]
rbd_data.87fa3437b808.0000000000000000
rbd_data.87fa3437b808.0000000000000001
rbd_data.87fa3437b808.00000000000000a0
rbd_data.87fa3437b808.0000000000000140
rbd_data.87fa3437b808.00000000000001e0
rbd_data.87fa3437b808.0000000000000280
rbd_data.87fa3437b808.0000000000000320
rbd_data.87fa3437b808.00000000000003c0
rbd_data.87fa3437b808.0000000000000460
rbd_data.87fa3437b808.0000000000000500
rbd_data.87fa3437b808.0000000000000501
rbd_data.87fa3437b808.0000000000000502
rbd_data.87fa3437b808.00000000000005a0
rbd_data.87fa3437b808.0000000000000640
rbd_data.87fa3437b808.00000000000006e0
rbd_data.87fa3437b808.0000000000000780
rbd_data.87fa3437b808.0000000000000820
rbd_data.87fa3437b808.00000000000008c0
rbd_data.87fa3437b808.0000000000000960
rbd_data.rbd_data.00000000000009ff
...
|
rbd_data数据井然有序,查看下 第一个data内容
1
2
3
4
5
6
| [root@node29 hrp]
00000000 58 46 53 42 00 00 10 00 00 00 00 00 00 28 00 00 |XFSB.........(..|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 e7 f1 7c c2 16 09 4b fc ba 61 4e fd b0 8d 18 2f |..|...K..aN..../|
[root@node29 ~]
-rw-r--r-- 1 root root 4.0M Aug 2 20:15 tmp1
|
可以确定,块格式化为 xfs时候 ,是有对块读写数据的,每个 obj都是 4M,这也书上说的一样,ceph中会将大文件切割成 4M 大小的obj,而且都遵循 对象文件名都是 以
rbd_data.{block_name_prefix}.{index}命名(format 2 风格)
block_name_prefix作为全局唯一标识,在加上索引即可成为一个obj;
在ceph 设计原理与实现有一张图可以很好体现出 image的结构 ?()
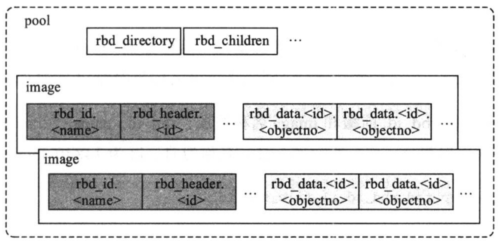
如果我在挂载的目录 新建一个有内容的文件,在 obj 文件中是否有更新呢?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
[root@node29 foo]
[root@node29 ~]
0000afc0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
0000afd0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
0000afe0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
0000aff0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
0000b000 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 67 |aaaaaaaaaaaaaaag|
0000b010 67 67 67 67 67 67 67 67 67 67 67 67 67 67 67 67 |gggggggggggggggg|
0000b020 67 67 67 67 67 0a 00 00 00 00 00 00 00 00 00 00 |ggggg...........|
0000b030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
0000b040 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
|
显然文件内容在 obj中可以找到,只不过被压缩编译了下。如果 写入一个大文件,会有什么变化呢?
1
2
3
4
5
6
7
8
9
10
| #这里写入一个 1G的 大文件
[root@node29 mnt]# dd if=/dev/zero of=/mnt/foo/maxfile count=1000 bs=1M
[root@node29 foo]# ls -lah maxfile
-rw-r--r-- 1 root root 1000M Aug 2 20:19 maxfile
[root@node29 foo]#
#在rbd pool里查看obj数量是否增加
[root@node29 mnt]# rados -p rbd ls | wc -l| sort
280
#原本才20几,现在290多个,1000/4=250 这样一算好像也差不多,符合上面说的,文件会分割成 4M大小obj
|
以上操作可以得出, rbd 生产 image 后,然后 map(这里用到的是 内核rbd)到操作系统,格式化,挂载使用;在挂载目录里面进行 crud操作,此时还没到 ceph pool 中,而是先通过 文件系统将数据整理后,在交给ceph,分割成4M对象文件(不一定都是是4M!!),接下来怎么操作是ceph底层的事情了。(后期结合代码更新)

文件是怎么分割的
待总结…..
思考的问题
以下是日常遇到RBD问题补充的
上文说到,数据通过编译后才看得到数据,这种是直接以二进制的方式来存放数据的,在RADOS还有两种存放数据的方式,第二种是 以键值对的方式(xattr),地方是也是键值对 omap方式