slow op的排查手段(更新中)
Last updated on 8 months ago
背景
slow op是cpeh 里面老生长谈的问题,像是牛皮癣,从底层看是op处理慢,从客户的业务层看重则卡死(例如 rbd挂载文件系统,底层 一直出现slow op现象,会y有可能触发文件系统的只读机制)轻则业务下发慢;
在线上遇到很多次,但也是偶发性的,往往是后续 巡检的时候才发现;最近遇到的一次是客户的对象存储业务经常卡顿,严重的时候直接请求直接失败,上线一看果然是slow op,这种严重情况比较少遇到过,以前也是只是偶尔出现slow 导致卡顿一会,这次只要一下业务就会出现;
出现的原因
表面原因: osd 底层处理 op时,因为底层是串行处理的(队列),如果有个别 io 处理时间比较长,则会阻塞到后面的op
osd 默认认为一个op 处理时间超过 osd_op_complaint_time (30s),就会有告警;
但为什么 op处理会很慢呢,但从这个告警是看不来什么,只有逐个方面的排查,才能知道根因,有时候甚至知道了根因也 无法马上消除这 slow op,业务压力大,但是 节点配置跟不上(诸如大量的随机读业务,而节点全是HDD,这个时候很容易出现 slow op)… 以下总结了这几个方向
硬盘的性能 瓶颈
最先可以看 硬盘是否到达瓶颈,首先得知道 客户的业务模型,如果是读业务很多,而客户全是 HDD 盘,没有sddcache 的话(大量读场景很容易达到HDD盘的性能),此时可以通过 iostat 命令来观察
那应该关注那些参数?
首先 util 的我们无需关注, 其次最要需要关注的是
- r_await : 磁盘上每个读 io的平均等待时间
- w_await : 磁盘上每个写io的平均等待时间
- svctm : 磁盘上每个io的平均处理时间
以下图所示 , r/s 尽管很大,但是 r_await ,svctm,都很小,可以推断此时磁盘并没有达到瓶颈

此外还需 要看下 demsg -T 查看最近一段时间,该磁盘有没有硬件报错,尤其是IO error方面的信息
网络问题
ping 各个节点,看看丢包情况,看看ping包的延时情况,是否稳定,如果忽高忽低,相差很大,那很有可能是网络问题引起的op传输受到影响
此外也可以参考 心跳的时延报警, ceph -s出现以下告警,则说明 心跳包接受有时延
iperf3打流测下带宽(这个需要每个节点都 有 iperf3 , 且 需要一方作为客户端,另一方作为服务端,此外使用这个需要去确定客户是否开启了 防火墙
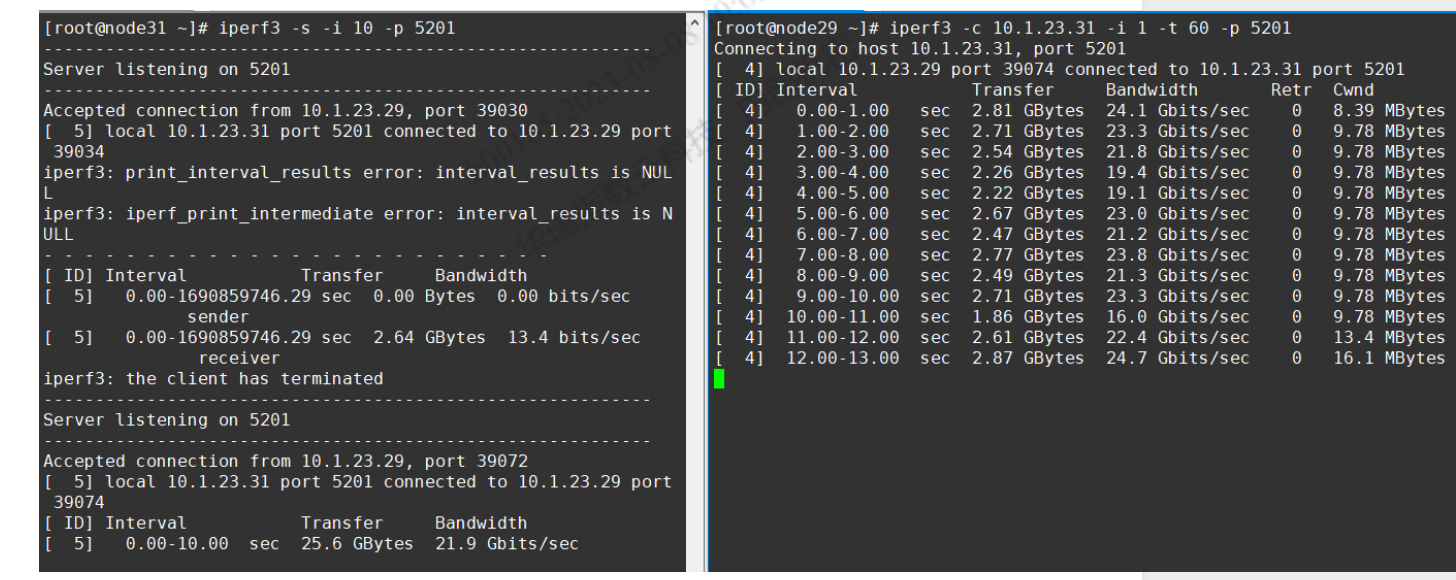
查看dmesg,看看网卡是否有相关报错信息,最常见的就是网卡发生了UP/Down,可能是线坏了或者插头松了,UP/Down会导致传输进行时产生丢包,tcp产生丢包对传输性能影响很大
分析 osd 的io 流程
查看那个 op 卡在那
通过ceph daemon [asok路径] dump_historic_ops可以看到 每个 op里的每个步骤 , (以下是正常 slow op,耗时 0.0001s)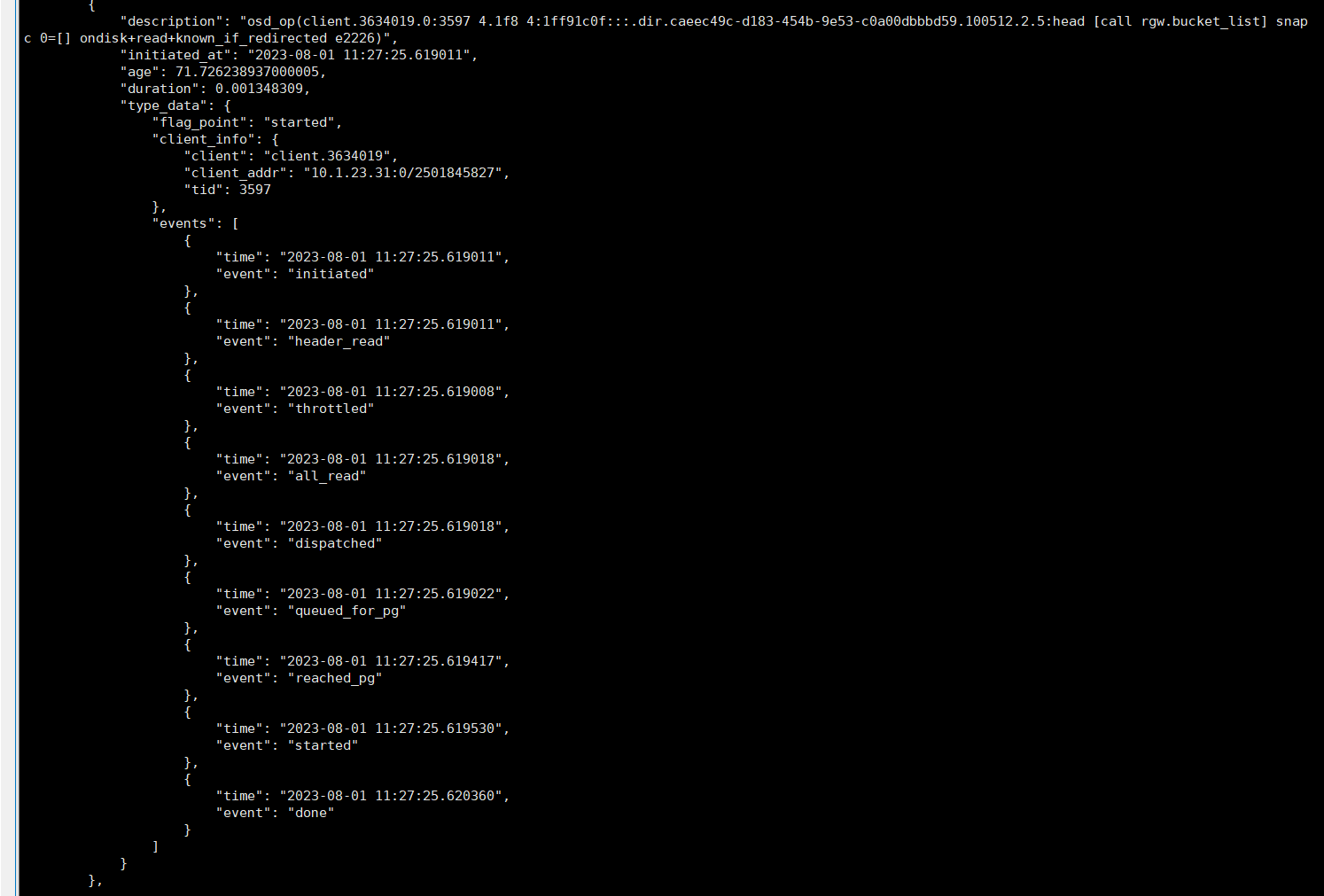
线上遇到slow 的时候往往 都是堵塞在
queued_for_pg这个步骤上 ,如下图所示 , 改op耗时 13s,其中 queued_for_pg 到 reached_pg 13s多,可见 百分之99的时间都花费在这这个步骤, 而 queued_for_pg 意思是: 改op已经被放到队列中,即将由它的PG进行处理,就是说等待了 时间全花在等待pg处理的上了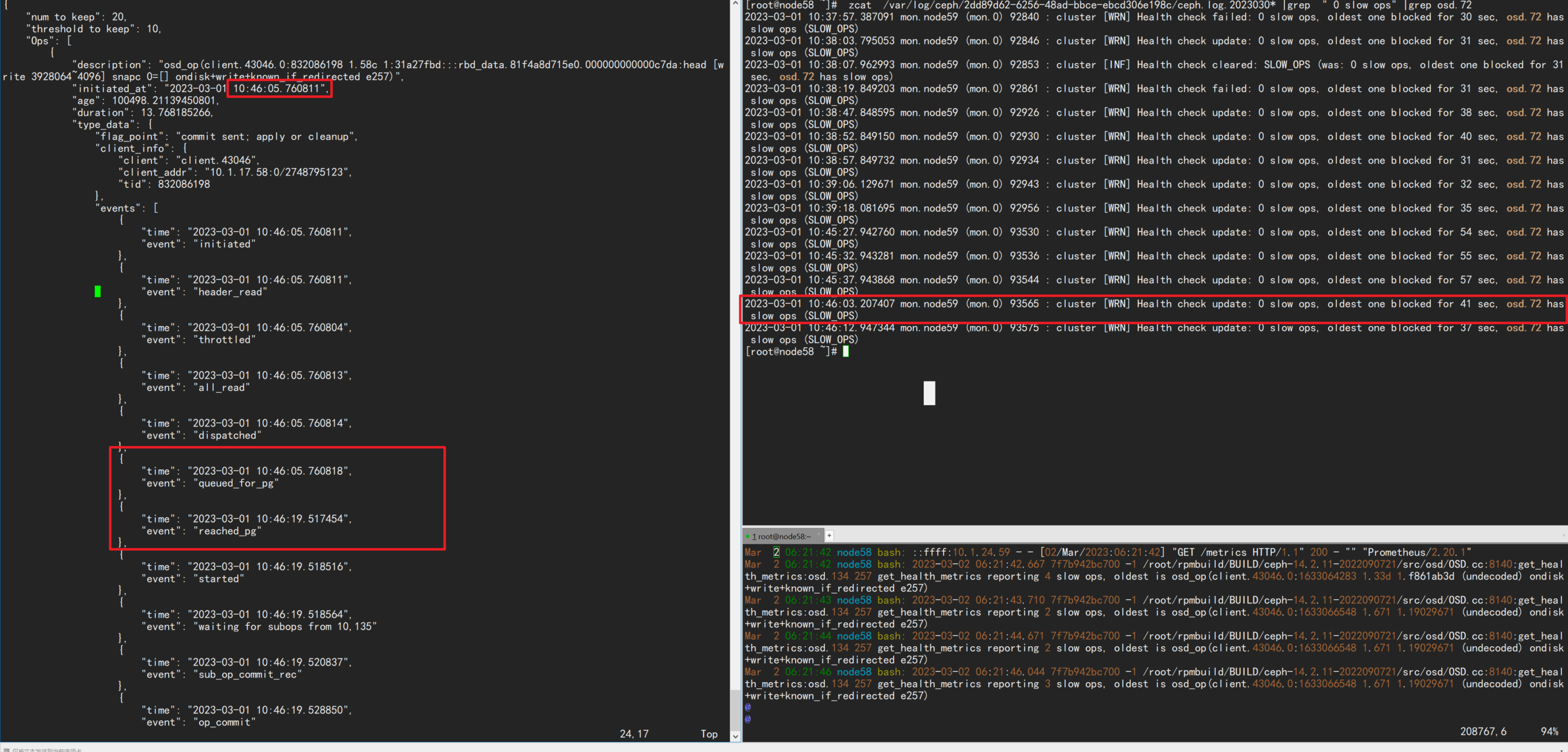
综合以上几点,总结了对于 此类问题,处理步骤
1、 首先 通过 ceph -s 看集群
对于此类 slow op问题,ceph -s 是最简单的观察方法, 会有告警提示我们 那些osd/mon 有slow op 并且堵塞了多少秒(原因并没有给出来)
此外还需要需要关注的是:
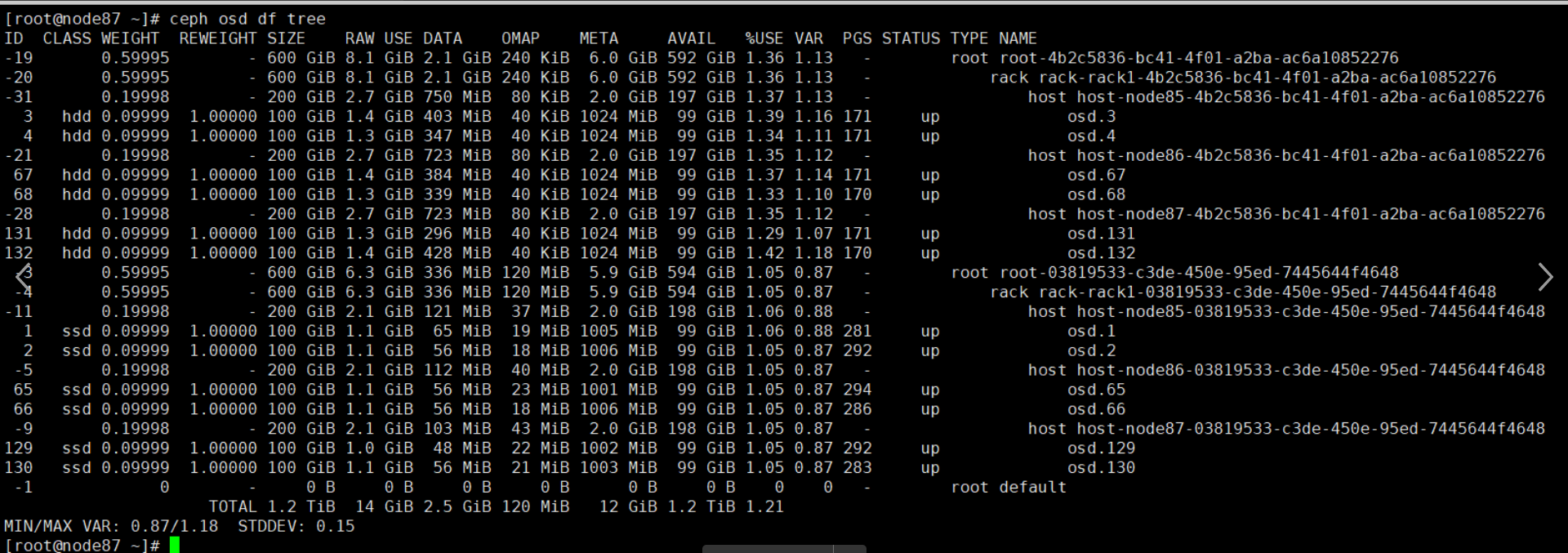
osd 状态 ceph osd df tree
- 查看osd 状态 : 是否为 up ( 可以在一个新的窗口 执行 ceph -w 方便持续观察 集群osd 的变化 ,因为osd 可能反复up/down )
- 以及osd数据分布: 数据是否分布均衡(主要关注 各个osd 上的 omap数量 ,pg 数量,以及集群内osd 数量)
- 实际案例: 客户环境 bi池 上的omap过多,导致 bucketlist 操作缓慢,出现slow op,阻塞了其他op,导致客户业务频繁超时; 原因是 omap上 无效数据过多,
osd容量 : 关注 osd 容量是否 达到集群容量的几种状态
(如果出现 ceph -s 可以观测到 nearfull,nearfull,backfillfull)
nearfull : 一个或多个OSD 已超过nearfull阈值(默认是**80%**)此警报是集群即将满的早期警告
full 一个或多个 OSD 超出了 full 阈值 (默认是 **90%**),阻止集群处理写入操作
backfillfull : 一个或多个 OSD 超出了 backfillfull 阈值(默认是 **85%**),因而不允许将数据重新平衡到此设备
failsafe_full : 一个或多个 OSD 超出了 failsafe_full 阈值 (默认是 97)**
以上前三个参数都可以通过以下参数设置, 最后一个failsafe_full** 由 osd_failsafe_full_ratio 配置1
2
3ceph osd set-backfillfull-ratio ratio
ceph osd set-nearfull-ratio ratio
ceph osd set-full-ratio ratio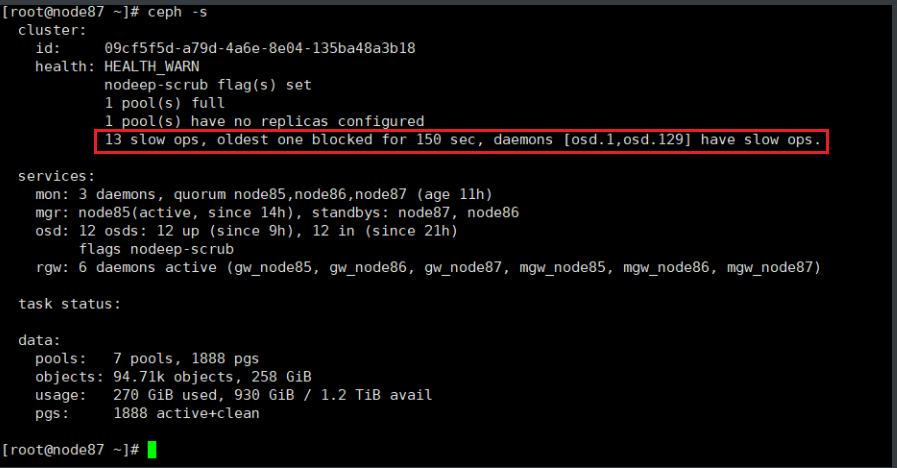
2、 查slow op相关日志(找到时间点)
slow op 相关 日志可以 ceph.log 都能搜出来,关键字: slow request
**2023-08-08 05:01:18.844780 osd.129 (osd.129) 79105 : cluster [WRN] slow request osd_op(client.78082.0:61239 4.1 4:93e5b521:::notify.7:head [watch ping cookie 94657425237248] snapc 0=[] ondisk+write+known_if_redirected e1469) initiated 2023-08-08 05:00:37.904017 currently delayed**
**{日志时间戳} {osd的id****} : cluster [WRN] slow request osd_op {(客户端id pg pg_seed:::{对象名字} )} initiated {op建立 时间} {op当前状态}**
这条日志你能得什么?
- slow op 发生的时间点 : 2023-08-08 05:01:18.844780
- slow op 发生在哪个osd上 : osd.129 (osd.129)
- slow op 操作那个那些对象 : ( 个别slow op没有显示)


3、osd 日志
已经知道了 slow op 发生的时间 和 所在的osd ,接下来 是要排查由 slow op 引发其他 异常
- 线程超时: 对于每个业务io,都会交由 一个线程负责处理,对于线程操作而言 处理op超时时间为15s ,超过15s ,会导致无法回复其他osd的心跳(内部检测机制)
关键字 had timed out after 
- osd 日志中 也可以看到 心跳异常
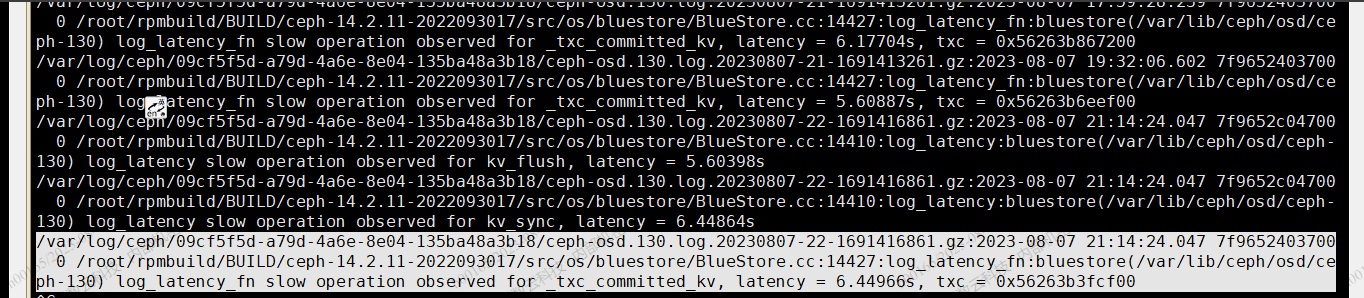
关键字: no reply 直接 参考 步骤 8 - bluesotre 层的操作 超过 5s时候,osd 会打印相关操作 日志 关键字 log_latency_fn
4、slow op卡在那个环节那个步骤中 (使用admin socket)
场景1 ,当下遇到了 slow op 可以使用 **ceph daemon {asok} ops** 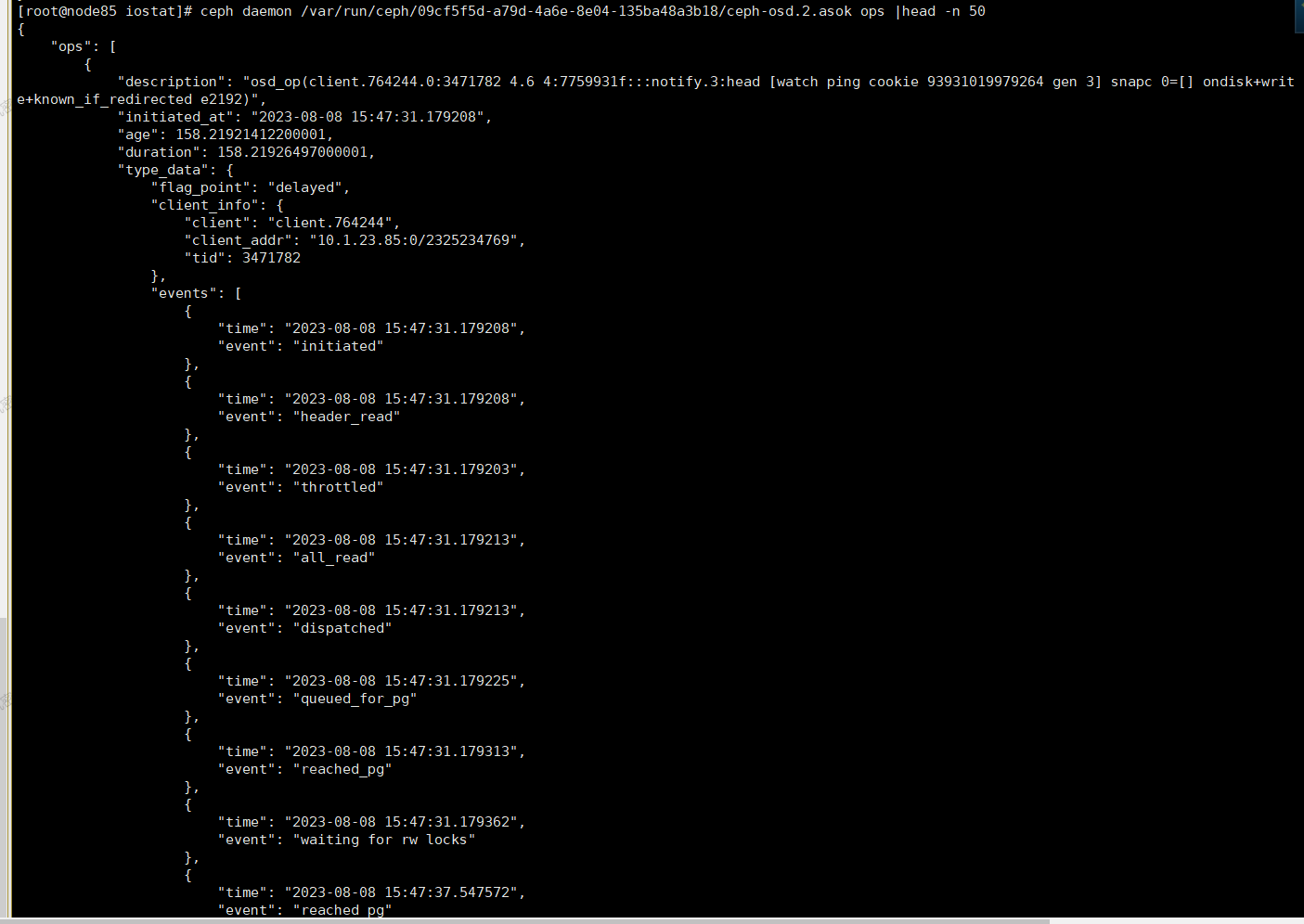
每个 osd op里面包含了很多 event ,通过dump 出来的内容,观察到 一个op的时长,和op中每个步骤的耗时;场景2 , 当下没有slow ,但是以前出现过,可以用 dump_historic_slow_ops 查看,但是改命令局限于 只能打印,过去10分钟内的10条slow op信息 **`ceph daemon {asok} dump_historic_slow_ops `**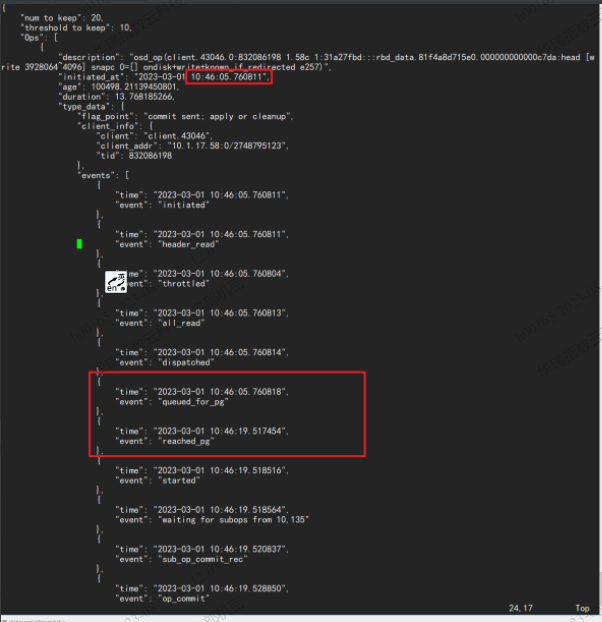
op中每一个event 都进行介绍下(等看完 io流程再完善…)
| 事件名 | 时间点 | 备注 |
|---|---|---|
| header_read | 收到 messenger 的时 | |
| throttled | message 获取内存节流空间以将消息读入内存时 | |
| all_read | 读取message 读取完消息时 | |
| dispatched | 消息分发给osd的时候 | |
| queued_for_pg | op已经被放到队列中,即将由它的PG进行处理 | 多数情况下,op 都堵塞在这里 |
| reached_pg | PG开始处理op | |
| started | OSD开始处理op | |
| waiting for subops from { osd.id } | op发送给副本OSD | |
| waiting for rwlock | 等待锁 | |
| commit_sent | 向客户端或者主OSD发送回复 | |
| op_commit | 操作已提交 |
5、查磁盘性能(慢盘)
上两步 知道 有那些 osd 有slow op,并且也通过 ceph.log 知道 slow op 发生的时间点
现在找到 osd 对应的磁盘,看磁盘是否达到瓶颈(这里提供了底层快速获取 osd 对应磁盘的脚本)
ceph osd metadata osd.$i : 可以查看 osd 绝对大部分信息
1 | |
对于iostat 这里我们主要关注两个 ()
await: 每个IO请求的处理的平均时间(以毫秒为单位)
svctm:表示平均每次设备I/O操作的服务时间(以毫秒为单位)
如果 磁盘 await 和 svctm 参数很大, 很有可以是 业务压力过大磁盘处理不过 osd 下发的io,从而导致了slow op

对于磁盘也有可能出现坏道 ,也可能出现 EIO
这种情况 ,可以在通过 slow op 出现时间点 在 mesage 中 查找
message 日志也会错误,关键字( 盘符 print_req_error 、 Buffer I/O)
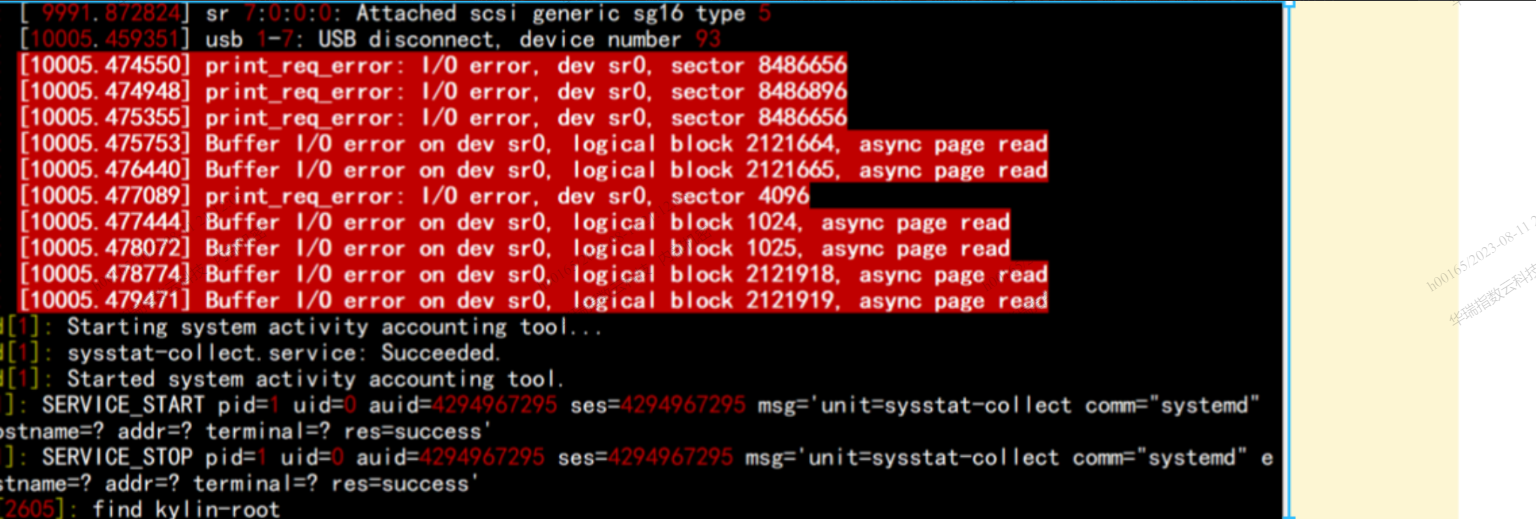
比如这里 是 osd.1 对应的是 sdb, 那我们就通过 iosta 看
这里我们主要关注
- await: 每个IO请求的处理的平均时间(以毫秒为单位)
- svctm:表示平均每次设备I/O操作的服务时间(以毫秒为单位)
如果 osd 对应磁盘 这两个参数很大, 很有可以是 磁盘 性能达到瓶颈

6、 查看网络时延
最直接的方法 ping 各个节点的网络看时延 (如果时延很大,一般来收 ceph -s 你就可以看到心跳 时延的告警了)
也可以用osd 之间心跳 的时延作为参考 ,用 admin-socket 可以dump
ceph daemon {asok 文件} dump_osd_network [时延上限值]
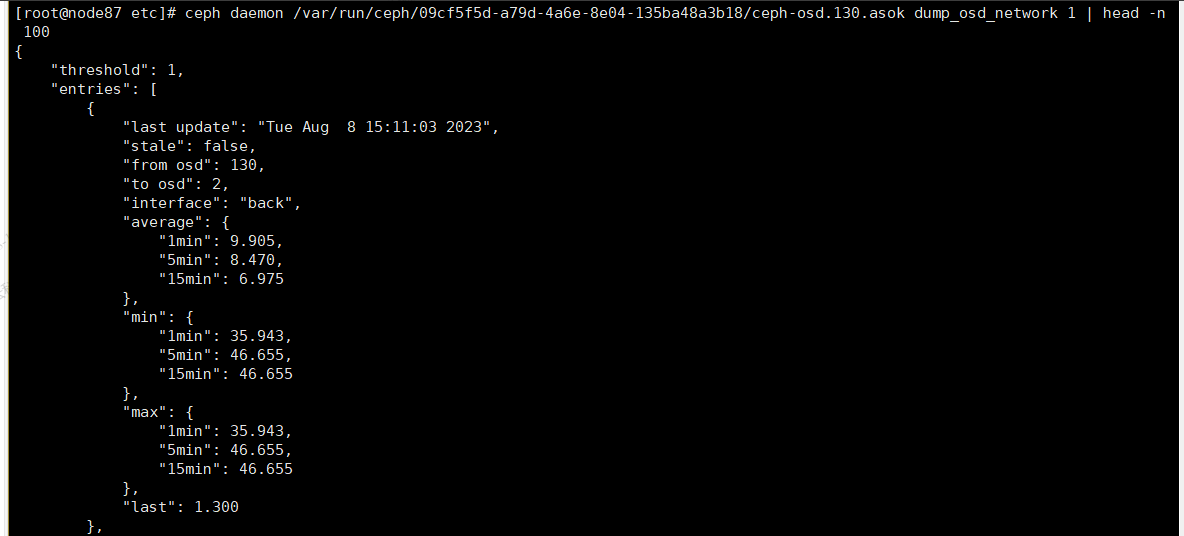
参数解释:
**last update : 心跳更新**
**stale: 是否延迟**
**from osd: 心跳从那个osd发过来**
**to osd: 心跳发送到那个osd**
**interface: 那个网络平面**
**average: 平均时延**
**min/max: 1min 内 平均时延**
**5min 内 平均时延**
**10min 内 平均时延**
**last: 最近得一次心跳时延**
7、看系统日志 messag
主要关注 message 日志和 dmseg 的输出
对于message :
磁盘IO 错误 关键字 : ( print_req_error 、 Buffer I/O)

OOM 关键字 : Out of memory

8、心跳方面问题
osd 与osd 之间会定期发送心跳包用来确认osd 是否有异常,mon 会根据osd 上报的异常信息处理
问题1 :
现象: ceph -s 出现
Long heartbeat ping times on back interface seen, longest is 3123 msecCEPH 日志 : OSD_SLOW_PING_TIME_BACK OSD_SLOW_PING_TIME_FRONT
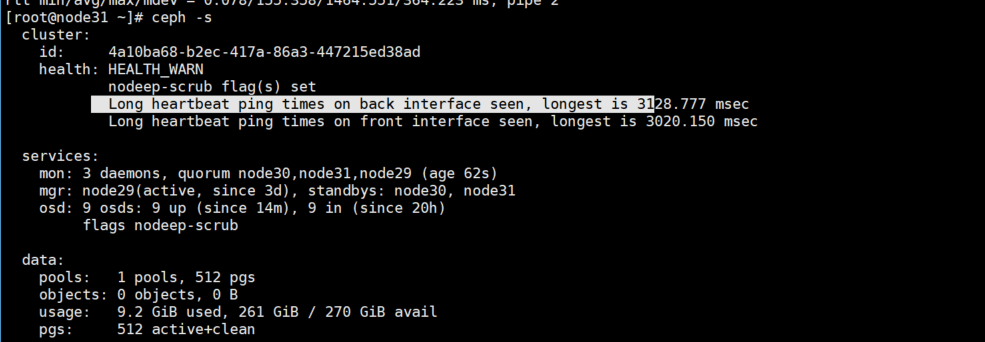
原因 : 节点间出现时延高问题(参考 步骤6),心跳正常,只是很慢(osd 最好容忍期限是 20s)
问题2:
现象: osd 日志中出现
no rply from, 下图的osd.1 没有有心跳回应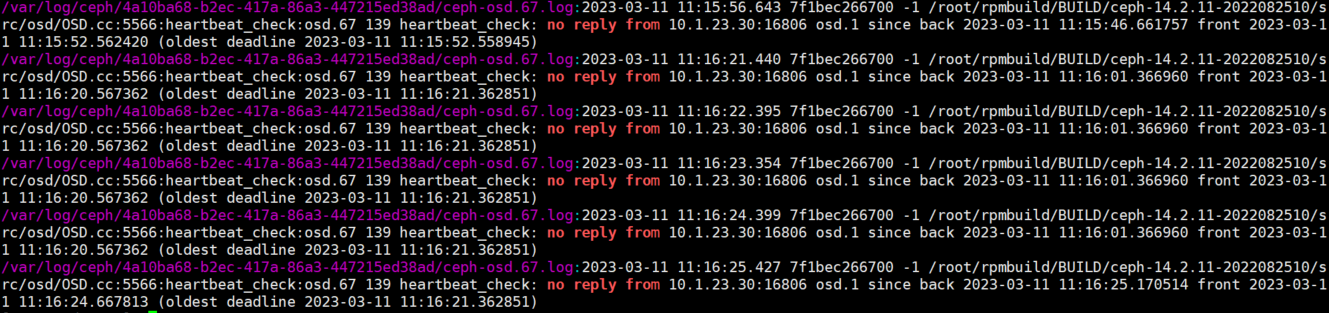
原因(主要是还是排查网络是否有异常):
- 日志表现是 osd 超时了,没有回复心跳,没有回复的原因可能有如下几种
- 网络异常导致 丢包了,甚至无法通信
- osd 再回复心跳前自检(核查 进程内的线程操作是否超时),如果自检不通过则不发回复心跳 (参考 步骤3 的 线程超时)

- 日志表现是 osd 超时了,没有回复心跳,没有回复的原因可能有如下几种