raft 论文翻译
Last updated on 8 months ago
raft论文,这里我计划j将论文翻译了一遍,原本是不翻译的,单纯看看,但看了几章,又没有印象,而且没有输出,只是单纯看了而已,并没有思考;当然这里这里并不是全部机翻,结合我的当下的理解来翻译,也不是全文翻译,有些重要的我就贴出原文,后续再来完善;
一段一段翻译,… 代表跳过(不是重点)有一些名字我直接用 单词,我感觉翻译出来很怪….
这个网站有raft 动态 http://thesecretlivesofdata.com/raft/
```mermaid ··· 绘图指令 ··· ```
In Search of an Understandable Consensus Algorithm
1 Introduction
一致性(共识)算法允许一组机器作为一个连贯的团队工作,可以在一些成员的失败中幸存下来;它们在构建可靠的大型软件系统中发挥着关键作用。在过去的十年里,Paxos(也是一种公识算法)主导着共识算法的讨论:大多数共识的实现是基于Paxos或受到它的影响,Paxos已经成为教授学生共识的主要工具。
…接下来几段 说 Paxos比较难以理解,于是作者就实现了另外一种 公式算法 raft
Raft在许多方面与现有的共识算法相似,但它有几个新的特性:
Strong leader: Raft uses a stronger form of leadership than other consensus algorithms. For example,log entries only flow from the leader to other servers. This simplifies the management of the replicated log and makes Raft easier to understand.
相对于其他共识算法Raft使用了更强的领导形式;比如日志记录只能从 leader状态的服务器流入其他服务器。这就简化了复制日志的管理并且是的Raft 更容易理解。
Leader election: Raft uses randomized timers to elect leaders. This adds only a small amount of mechanism to the heartbeats already required for any consensus algorithm, while resolving conflicts simply and rapidly.
Raft 使用随机定时器来选举 leader。这只是为已有心跳机制的共识算法添加了少量的机制,同时又可以快速容易的解决冲突。
Membership changes: Raft’s mechanism for changing the set of servers in the cluster uses a new joint consensus approach where the majorities of two different configurations overlap during transitions. This allows the cluster to continue operating normally during configuration changes.
Raft 更改集群中服务器集的机制使用了一种新的联合共识方法,其中两种不同配置中的大多数在转换期间重叠。这允许群集在配置更改期间继续正常运行。
第二章介绍复制状态机的问题
第三章讨论Paxos优缺点
第四章 介绍了可以理解行的一般方法
第五到八章节介绍 Raft共识算法
2 Replicated state machines
共识算法经常出现在副本转态的上下文中。在这个方法中,一组服务器上的状态机会计算相同的副本,及时有服务器挂掉了掉了,也可以运行。在分布式系统中,副本状态机用来解决各种容错性问题。….
副本转态机的是通常用于复制日志来实现的,如图 1。每一个服务器都存储着包含命令的日志,这些状态机按照这些命令依次执行。每一个状态机都包含了顺序相同的日志,并且要按照这个顺序执行。由于状态机是确定性的,每一次计算都有相同状态,都有相同输出。
图1
Replicated state machine architecture. The consensus algorithm manages a replicated log containing state machine commands from clients. The state machines process identical sequences of commands from the logs, so they produce the same outputs.
副本状态机架构:一致性算法管理一个包含来自客户端的状态机命令的复制日志。状态机处理来自日志的相同的命令序列,所以会有相同的输出。
保持副本日志一致是共识算法的任务,共识模块在服务器上收到客户端的命令并添加到他们各自的日志中。在其他服务器上也是通过共识模块交流以确保每一个日志 最终包含相同的顺序以及相同的请求,即使有服务器有宕机了。一旦命令被正确的复制,每个服务器的状态机会按照顺序处理这里命令,并且输出会返回客户端。最终的结果就是服务器看起来是单一,高可用的状态机。
在一个可行的系统中共识算法通常有以下几点特性:
They ensure safety (never returning an incorrect result) under all non-Byzantine conditions, including network delays, partitions, and packet loss, duplication, and reordering.
确保安全。。。
They are fully functional (available) as long as any majority of the servers are operational and can communicate with each other and with clients. Thus, a typical cluster of five servers can tolerate the failure of any two servers. Servers are assumed to fail by stopping; they may later recover from state on stable storage and rejoin the cluster.
只要有服务器能操作并且能和其他服务器进行交流,以及和客户端通信,那么这些功能就是可用的。因此,一个典型的集群服务器,一般可以容忍两个服务器宕机;服务器假如停止,它们稍后从稳定存储上的状态恢复并重新加入集群。
They do not depend on timing to ensure the consistency of the logs: faulty clocks and extreme message delays can, at worst, cause availability problems.
它们不依赖于时序来确保日志的一致性: 错误的时钟和极端的消息延迟在最坏的情况下会导致可用性问题。
In the common case, a command can complete as soon as a majority of the cluster has responded to a single round of remote procedure calls; a minority of slow servers need not impact overall system performance.
通常情况下,集群大多数的节点有回复 远程调用调用就意味这个命令是完成的,一些慢节点是不会整体系统的性能
3 What’s wrong with Paxos?
4 Designing for understandability
5 The Raft consensus algorithm
Raft 是一种共识算法用来管理第二章所描述的副本日志。图2 总结了算法的概要,图3列举了算法的关键属性,这两个图的关键点在剩余的章节都会讨论到。

Raft 首先选举出一名 突出的 “leader”,然后给与这个leader 责任去管理副本日志。leader从客户端接受日志条目复制到其他服务器,并且告诉其他服务器何时将日志条目应用到其状态机是安全的。拥有一个 “leader”可以简化复制日志的管理工作。比如“leader” 可以 放置性的日志条目不用考虑其他的服务器,并且简化leader到服务起的数据流。 leader可能会 fail或者 和集群断开链接,这种情况下,会选举出新的leader。
distinguished
根据领导方法,Raft将共识问题分解为三个相对独立的子问题,这将在下面的小节中进行讨论:
Leader election: a new leader must be chosen when an existing leader fails (Section 5.2).
Log replication: the leader must accept log entries from clients and replicate them across the cluster,forcing the other logs to agree with its own (Section 5.3).
Safety: the key safety property for Raft is the State Machine Safety Property in Figure 3: if any server has applied a particular log entry to its state machine,then no other server may apply a different command for the same log index.
Section 5.4 describes how Raft ensures this property; the solution involves an additional restriction on the election mechanism described in Section 5.2. After presenting the consensus algorithm, this section discusses the issue of availability and the role of timing in the system.
5.1 Raft basics
一个Raft 集群包含多个服务器;5台服务器是一个典型的配置,它允许系统容忍两次故障。在任何给定的时间内,每个服务器都处于以下三种状态之一:leader, follower, 和candidate.一般来说有一个明确的leader剩下服务器都是follwer。follwer是被动的:他们自己不发出任何请求但只回复leader 和 candidate的请求。leader处理客户端的全部请求。
Raft会将时间分成一个长度,每一个时间段都用序号标明。每个时间段都会选举一次,有很多的candidater 都会参与并尝试称为 leader。如果 candidate 赢得了选举,在这个时间段内都是它来当leader。有些情况可以会出现选举会有分裂情况 (票数相同?),那么这个时间段就不会产生 leader,新一轮的选举会马上开始。Raft确保最多只有一个leader在一个时间段内。
不同的服务器在不同的时间内,观察到的状态可能不同,并且一些环境下服务器可能也观察 不到选举。在Ratf中 ,Terms 扮演了一个逻辑时钟,他们允许服务器检测到过时的信息。每个服务器都存储着一个当前的期间编号,编号会随时间单调。没当服务器交换通信,当前的term会被交换,如果一个服务器的term小于俩一个服务器,则它会将其当前时间段更新为更大的值。如果一个候选人或领导者发现它的任期已经过时,它会立即恢复到追随者的状态。如果服务器接收到一个术语号陈旧的请求,那么它将拒绝该请求。
之间通信使用RPC进行通信,基于一致性的算法只需要两种RPC方式,在candidate状态期间使用 请求投票的RPC发起的,leader 复制日志条目和提供心跳形式,是由Append Entries RPC发起的。
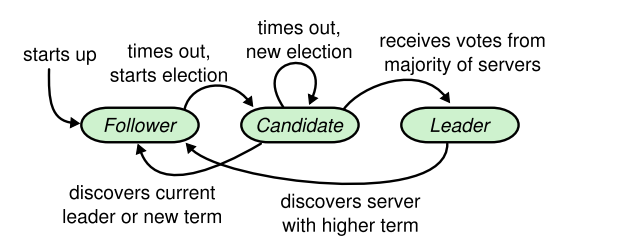
图四
服务器状态。追随者只响应来自其他服务器的请求。如果一个追随者没有接收到任何交流,它就会成为一个候选人并发起一场选举。从整个集群中获得多数选票的候选人将成为新的领袖。领导者通常会一直运作到失败为止。
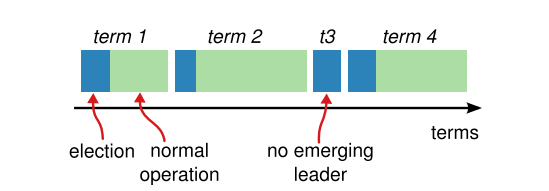 图五
图五
时间分为不同的任期,每个任期都从选举开始。在选举成功后,一个leader 管理集群,直到任期结束。有些选举失败了,在这种情况下,任期结束时没有选出一个leader。在不同的服务器上不同时间观察到术语之间的转换。
5.2 Leader election
Raft使用心跳机制来触发 leader选举。当服务器开始运作,服务器成为follower。只要收到leader 或者是candidate发送的有效 RPC服务器会一直保持follower状态。leader周期性地发送心跳给全部follower,用以保证leader的地位,如果一个follower没有收到RPC消息在一段选举超时的时间内,随后改服务器假设没有leader并会发起一场选举用来选择新的leader。
选举开始时候,follower 增加当前的 term,并转换为 candidate转态,然后为自己投票,与在集群中的其他服务器发起投票请求的RPC。candidate 持续保持这种转态直到以下三件事有一件事发生之前:
(a) 自己获胜
(b) 其他服务器获胜
(c)过了一段时间后,还没有 leader产生重新开始这个选举
以上的结果会在接下来的段落中分来讨论
一个candidate 如果在同一时期获得了集群中大多数的服务器的投票,那么它将赢得这场选举。在先到先得的基础上,每个服务器将会投票给一个candidate在一个term中。大量规则会确保最多只有一个candidate赢过得选举冠军。一旦candidate赢得选举,它就会成为 leader,并发送心跳包信息给其他服务器用来通知其他人并且会阻止新的选举
在等待投票期间,candidate可能收到 来自声称自己的是leader发过来的类型为添加条目(AppendEntries RPC)的RPC。如果当前 的leader 任期最少比candidate的周期大,那么candidate会承认leader是合法的,并切换会 follower状态,若果小于,那么候选人将拒绝 对方发来的rpc 信息,继续保持 候选人的状态。
第三种结果是 每个候选人都没有输赢: 如果很多 follows在相同的时间点 都成为 candidate,这也可能选票可以被分割,这样就不会有候选人获得多数选票; 但这种情况发生的时候,candidate 主主动超时,并且重重新新的选举,然而如果没有额外的措施,会产生分裂,会一直重复这种错误;
Raft中选举超时时间是随机的,以确保不会发生投票分裂的情况,并且可以快速的解决。为了防止投票分裂,选举暂停是从固定间隔中随机选择的(150-300ms)。扩展的服务器上,在大多 数情况下,只一个服务器会超时;它会赢得选举和发送心跳包在其他服务器超时之前。相同的机制也可以处理投票分裂的情况。每一个 candidate 都会重启它的随机超时选举在选举开始时,并在开始下次选举之前等待该超时过去;这降低了新选举中另一次分裂投票的可能性。
选举是一个例子,说明可理解性如何指导我们在设计方案之间做出选择。最初我们计划使用一个排名系统:每个候选人被分配一个唯一的排名,用于在竞争候选人之间进行选择。如果一个候选人发现了另一个排名更高的候选人,它就会回到追随者状态,这样排名更高的候选人就更容易赢得下一次选举。我们发现这种方法在可用性方面产生了微妙的问题(如果排名较高的服务器失败,排名较低的服务器可能需要超时并再次成为候选服务器)
5.3 Log replication
一旦选出了一个leader ,它就会开始为客户的请求提供服务。每个客户端请求都包含一个要由复制的状态机执行的命令。leader 将该命令作为一个新条目( entry,以后都用entry )添加到其日志中,然后向每个其他服务器并行地发出 AppendEntries RPC,以复制该条目。当条目被安全复制后,leader将该条目应用到其状态机,并将该执行的结果返回给客户端。如果追随者崩溃或运行缓慢,或者网络数据包丢失,leader 会无限期地重试应用程序项rpc(即使在它对客户端做出响应之后)。
日志的组织方式如图6所示。当leader 接收到条目时,每个日志都存储一个状态机命令和一个时间端编号(下面 用term 来表达)。日志条目中的term 用于检测日志之间的不一致。每个日志条目也有一个整数索引,标识其在日志中的位置。

leader决定何时对状态机应用日志条目是安全的;想这样的日志条目称为已提交。Raft保证已提交的条目是持久的,并最终将由所有可用的状态机执行。一旦leader创建的日志条目被大多数服务器复制,就会提交日志条目。这样的做法也提交了leader 的日志条目,包括先前 leader创建的条目。第5.4节讨论了在 leader 变更后应用此规则时的一些微妙之处,它也表明了这个承诺的定义是安全的。leader会跟踪它知道已提交的索引,并将改索引包括在未来的 future AppendEntries RPCs中,以至于其他服务器可以找到。当一个 follower知道这条日志是 commit的就会在本地应用这条日志。
我们设计了raft日志机制,以保持不同服务器上的日志之间的高度一致性。这不仅简化了系统的行为,使其更可预测,而且是确保安全的一个重要组成部分。
raft维护两个属性
如果不同log 中的两个具有相同的 index 和 term,则它们存储相同的命令。
如果不同log中的两个条目有相同的 index 和 term ,那么前面所有entry都是相同的。
第一个属性源于这样一个事实:一个 leader 在一个给定的期限中最多创建一个具有给定日志索引的条目,并且日志条目永远不会改变它们在日志中的位置。
第二个属性是由担保人执行的一个简单的一致性检查来保证的。当发送一个Append-Entries RPC时候,leader会在新条目生成之前包含日志条目的索引和期限。
如果 follower在日志中没有找到具有相同的索引和期限的日志条目,它会拒绝这个新条目。一致性检查作为一个归纳步骤:日志的初始空状态满足日志匹配属性,并且每当扩展日志时,一致性检查都会保留日志匹配属性。因此,每当Append-Entries RPC成功返回时,leader 就知道关注者的日志与其通过新条目的自己的日志是相同的。
在正常运行过程中,leader 和 follower 的日志保持一致,因此 AppendEntries RPC 一致性检查不会失败。但是,leader 崩溃可能会使日志不一致(旧的 leader 可能没有完全复制其日志中的所有条目)。这些不一致可能会加剧一系列追随者的崩溃。图7说明了关注者的日志可能与新领导者的日志之间的不同方式。
 图7
图7
在Raft中 ,leader 通过强制 使 follower的日志复制自己的日志用来处理不一致。这意味着 follower 日志中的冲突条目将被引头日志中的条目所覆盖。第5.4节将表明,如果附加一个限制,这是安全的。
要使得跟随者的日志进入和自己一致的状态,领导人必须找到最后两者达成一致的地方,然后删除跟随者从那个点之后的所有日志条目,并发送自己在那个点之后的日志给跟随者。所有的这些操作都在进行附加日志 RPCs 的一致性检查时完成。领导人针对每一个跟随者维护了一个 nextIndex,这表示下一个需要发送给跟随者的日志条目的索引地址。当一个领导人刚获得权力的时候,他初始化所有的 nextIndex 值为自己的最后一条日志的 index 加 1(图 7 中的 11)。如果一个跟随者的日志和领导人不一致,那么在下一次的附加日志 RPC 时的一致性检查就会失败。在被跟随者拒绝之后,领导人就会减小 nextIndex 值并进行重试。最终 nextIndex 会在某个位置使得领导人和跟随者的日志达成一致。当这种情况发生,附加日志 RPC 就会成功,这时就会把跟随者冲突的日志条目全部删除并且加上领导人的日志。一旦附加日志 RPC 成功,那么跟随者的日志就会和领导人保持一致,并且在接下来的任期里一直继续保持。
如果需要的话,算法可以通过减少被拒绝的附加日志 RPCs 的次数来优化。例如,当附加日志 RPC 的请求被拒绝的时候,跟随者可以(返回)冲突条目的任期号和该任期号对应的最小索引地址。借助这些信息,领导人可以减小 nextIndex 一次性越过该冲突任期的所有日志条目;这样就变成每个任期需要一次附加条目 RPC 而不是每个条目一次。在实践中,我们十分怀疑这种优化是否是必要的,因为失败是很少发生的并且也不大可能会有这么多不一致的日志。
通过这种机制,领导人在获得权力的时候就不需要任何特殊的操作来恢复一致性。他只需要进行正常的操作,然后日志就能在回复附加日志 RPC 的一致性检查失败的时候自动趋于一致。领导人从来不会覆盖或者删除自己的日志(图 3 的领导人只附加特性)。
日志复制机制展示出了第 2 节中形容的一致性特性:Raft 能够接受,复制并应用新的日志条目只要大部分的机器是工作的;在通常的情况下,新的日志条目可以在一次 RPC 中被复制给集群中的大多数机器;并且单个的缓慢的跟随者不会影响整体的性能。
5.4 Safety
在前面的几个章节描述了raft的选举和日志复制。然而,前面所描述的机制还不足以确保每个状态机以相同的顺序执行完全相同的命令。比如,当leader提交几个日志条目时,follower 可能不可用,然后这 follower 可能被选为leader,并用新条目覆盖这些条目;因此,不同的状态机可能执行不同的命列,因此,不同的状态机可能会执行不同的命令序列。
5.4.1 Election restriction
前面的章节里描述了 Raft 算法是如何选举和复制日志的。然而,到目前为止描述的机制并不能充分的保证每一个状态机会按照相同的顺序执行相同的指令。例如,一个跟随者可能会进入不可用状态同时领导人已经提交了若干的日志条目,然后这个跟随者可能会被选举为领导人并且覆盖这些日志条目;因此,不同的状态机可能会执行不同的指令序列。
这一节通过在领导选举的时候增加一些限制来完善 Raft 算法。这一限制保证了任何的领导人对于给定的任期号,都拥有了之前任期的所有被提交的日志条目(图 3 中的领导人完整特性)。增加这一选举时的限制,我们对于提交时的规则也更加清晰。最终,我们将展示对于领导人完整特性(Leader Completeness Property) 的简要证明,并且说明该特性是如何引导复制状态机做出正确行为的。
待更新