Last updated on 6 months ago
前言 在文件描述符文章中已经介绍 fd是如何生成的;原本想接下来 说下 fd 和 文件是怎么关联的,但是粗略的看了来整个过程,实在是太复杂,有很多前置的知识点,很难一下子展开讲,要讲明白的话不是一两篇文章能解决的;于是 打算围绕这个问题,再细分下来,逐个击破。
本章的内容 就先简单的介绍 文件路径再linux 中怎么解析的
在文件描述符介绍的文章中 也有讲过 open 函数,这里就不重复叙述怎么进入 do_sys_open 函数
先介绍几个关键的结构体
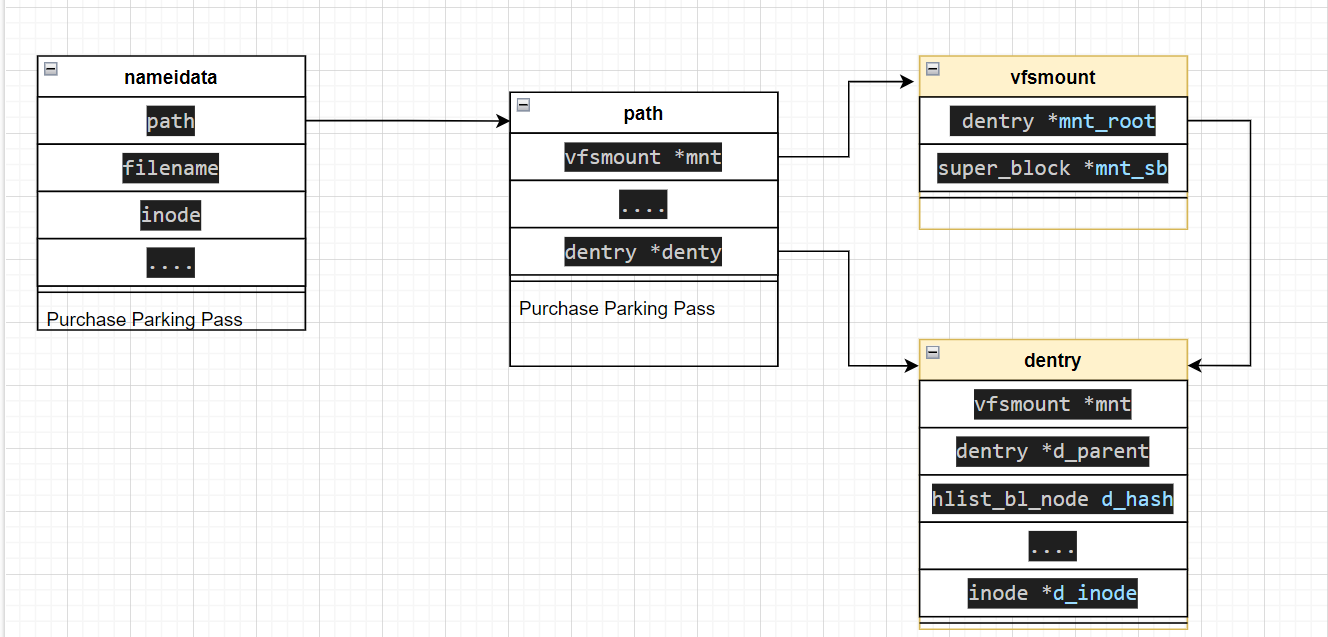
nameidata
nameidata结构体 会一直伴随着 路径解析的过程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 struct nameidata {struct path path ;struct qstr last ;struct path root ;struct inode *inode ;unsigned int flags; unsigned seq, m_seq; int last_type; unsigned depth; int total_link_count; struct saved {struct path link ;struct delayed_call done ;const char *name; unsigned seq; stack , internal[EMBEDDED_LEVELS];struct filename *name ;struct nameidata *saved ;struct inode *link_inode ;
file
一个file代表 一个打开的文件对象,通过 fd 可以找到这个 file ,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 struct file {union {struct llist_node fu_llist ;struct rcu_head fu_rcuhead ;struct path f_path ;struct inode *f_inode ;const struct file_operations *f_op ;fmode_t f_mode; struct mutex f_pos_lock ;loff_t f_pos; struct fown_struct f_owner ;const struct cred *f_cred ;struct file_ra_state f_ra ;#ifdef CONFIG_EPOLL struct list_head f_ep_links ;struct list_head f_tfile_llink ;
dentry
dentry (directory entry)记录了 父目录以及子目录项
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 struct dentry {unsigned int d_flags; seqcount_t d_seq; struct hlist_bl_node d_hash ;struct dentry *d_parent ;struct qstr d_name ;struct inode *d_inode ;unsigned char d_iname[DNAME_INLINE_LEN]; union {struct list_head d_lru ;wait_queue_head_t *d_wait; struct list_head d_child ;struct list_head d_subdirs ;union {struct hlist_node d_alias ;struct hlist_bl_node d_in_lookup_hash ;struct rcu_head d_rcu ;
主要关注do_sys_open 中的 do_filp_open 函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 long do_sys_open (int dfd, const char __user *filename, int flags, umode_t mode) struct open_flags op ;int fd = build_open_flags(flags, mode, &op);struct filename *tmp ;if (fd)return fd;if (IS_ERR(tmp))return PTR_ERR(tmp);if (fd >= 0 ) {struct file *f =if (IS_ERR(f)) {else {return fd;
do_filp_open fd申请成功的情况下, 才会开始路径解析, 该函数先 nameidata 初始化了 路径名字(先假设 文件路径绝对路径,为 /home/hrp/test) ,主要关注 path_openat 的实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 struct file *do_filp_open (int dfd, struct filename *pathname, const struct open_flags *op) struct nameidata nd ;int flags = op->lookup_flags;struct file *filp ;if (unlikely(filp == ERR_PTR(-ECHILD)))if (unlikely(filp == ERR_PTR(-ESTALE)))return filp;
path_openat 主要工作是,根据open 带的flag来分配一个 file ,接下来根据 这些flag 来判断进入不同 流程
**path_init **link_path_walk do_last (放在下篇文章讲)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 static struct file *path_openat (struct nameidata *nd, const struct open_flags *op, unsigned flags) struct file *file ;int error;if (IS_ERR(file))return file;if (unlikely(file->f_flags & __O_TMPFILE)) {else if (unlikely(file->f_flags & O_PATH)) {else {const char *s = path_init(nd, flags);while (!(error = link_path_walk(s, nd)) &&0 ) {if (likely(!error)) {if (likely(file->f_mode & FMODE_OPENED))return file;1 );
path_init 前面说到的 nameidata 也只是初始化 路径名,而在path_init 中会进一步初始化 nameidata
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 static const char *path_init (struct nameidata *nd, unsigned flags) const char *s = nd->name->name;0 ;NULL ;NULL ;NULL ;if (flags & LOOKUP_ROOT) {struct dentry *root =struct inode *inode =return s;if (*s == '/' ) {if (likely(!nd_jump_root(nd)))return s;return ERR_PTR(-ECHILD);else if (nd->dfd == AT_FDCWD) {if (flags & LOOKUP_RCU) {struct fs_struct *fs = current->fs;unsigned seq;do {while (read_seqcount_retry(&fs->seq, seq));else {return s;else {return s;
link_path_walk nameidata 初始化了 root ,root 里面包含了 目录” / “ 的dentry, 接下来看 link_path_walk 的实现,该函数也是 路径解析的关键函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 假设路径为 /home/hrp/abcstatic int link_path_walk (const char *name, struct nameidata *nd) while (*name == '/' )if (!*name)return 0 ;for (;;) {int type;if (name[0 ] == '.' ) switch (hashlen_len(hash_len)) {case 2 :if (name[1 ] == '.' ) {break ;case 1 :if (likely(type == LAST_NORM)) {struct dentry *parent =if (unlikely(parent->d_flags & DCACHE_OP_HASH)) {struct qstr this =if (err < 0 )return err;if (!*name)goto OK;do {while (unlikely(*name == '/' ));if (unlikely(!*name)) {if (!nd->depth)return 0 ;stack [nd->depth - 1 ].name;if (!name)return 0 ;else {if (err < 0 )return err;if (unlikely(!d_can_lookup(nd->path.dentry))) {if (nd->flags & LOOKUP_RCU) {if (unlazy_walk(nd))return -ECHILD;return -ENOTDIR;
walk_component 这里再分析下 walk_component , walk_component
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 static int walk_component (struct nameidata *nd, int flags) struct path path ;struct inode *inode ;unsigned seq;int err;if (unlikely(nd->last_type != LAST_NORM)) {if (!(flags & WALK_MORE) && nd->depth)return err;return step_into(nd, &path, flags, inode, seq);
lookup_fast 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 static int lookup_fast (struct nameidata *nd, struct path *path, struct inode **inode, unsigned *seqp) struct vfsmount *mnt =struct dentry *dentry , *parent =int status = 1 ;int err;if (nd->flags & LOOKUP_RCU) {unsigned seq;bool negative;if (likely(err > 0 ))return err;
总结 从 home/hrp/abc 得到hash 值, 在 **’/‘ ** 中的dentry找到 **’ home ‘**的 dentry ,更新 nameidata,
以此类推 直到找到 目录hrp所在的dentry 为止
下一篇文章介绍 解析到 hrp目录后,是怎么找到abc文件的
TODO:
是怎么通过 drenty hash到的
软连接,特殊字符(./ ../)怎么处理的
drentry 不在内存中,这种情况怎么处理?